2주 차에는 group by, order by와 그 외를 조금 배웠다.
쿼리가 실행되는 순서를 정확히 익히기 위해 다시 되새기는 것이 중요했다.
코딩은 정확하게 실수하지 않는 것이 중요한 거 같다.
물론 프로그램들이 똑똑해서 나의 오류를 금방 잡아내 주니까 좋다.

1. group by
select name, count(*) from users
group by name
라고 하면, users에 있는 유저의 이름들을 성씨별로 수를 세어달라는 요청이다.
이 명령어를 입력할 때는
select * from users
group by name
이라고 해서 users에 있는 이름들을 쭉 보여달라는 명령어가 기초가 된다.
이때 이름들이 너무 많으니 여기서 세어줬으면 한다는 명령어로 고치는 순서인 것이다.
물론 쭉 써도 되는 거지만,
쿼리가 구현되는 원리를 이해하자면 이런 방식으로 이해하고 있는 것이 좋겠다.
이때 만약 신 씨의 성을 가진 사람이 몇 명인지를 보고 싶다면, 두 가지 방법이 있다.
우선 전체 users에서 신 씨만 추려서 리스트를 만드는 방법이 있고,
앞서 썼던 group by로 묶어서 몇 명인지 카운트 숫자만 확인하는 방법이 있다.
select * from users
where name =“신**”
이라고 친 뒤 컨트롤 엔터 (실행)를 치면
신 씨 성을 가진 사람들의 목록이 뜬다.
다음으로는 group by의 최댓값 최솟값 구하기이다.
이번에는 checkins 데이터를 이용한다.
수강자들의 각 주차별 후기를 살펴볼 수 있는 데이터다.
주차별로 오늘의 다짐 개수 구하려면?
전체 checkins 목록에서 주차별로 묶어서 개수를 세어달라고 명령문을 쓰면 된다.
Select * from checkins
Group by week
전체 * 을 week, count (*)로 바꾸어 준다.
select week, count (*) from checkins
group by week
최솟값을 구하려면?
minimum의 축약어인 min을 쓴다.
count 자리에 쓰면 된다.
최댓값은 maximum의 축약어인 max를 쓴다.
평균값은 average의 축약어인 avg를 쓴다. 이건 알아두어야겠다.
여기까지 하니 강의명에서 왜 엑셀과 비교를 하는지 어렴풋이…
avg를 쓸 때 소수점이 보기 좋지 않다면,
round로 감싸서 소수점 뒤에 몇 자리까지 보여줄 것인지를 지정해주는 것이 좋다.
Select week, round (avg(likes),2) from checkins
Group by week
라고 쓰면, 소수점 2번째 자리까지 보여준다.
합계는 SUM이다. 완전 엑셀이다. ㅋㅋㅋ
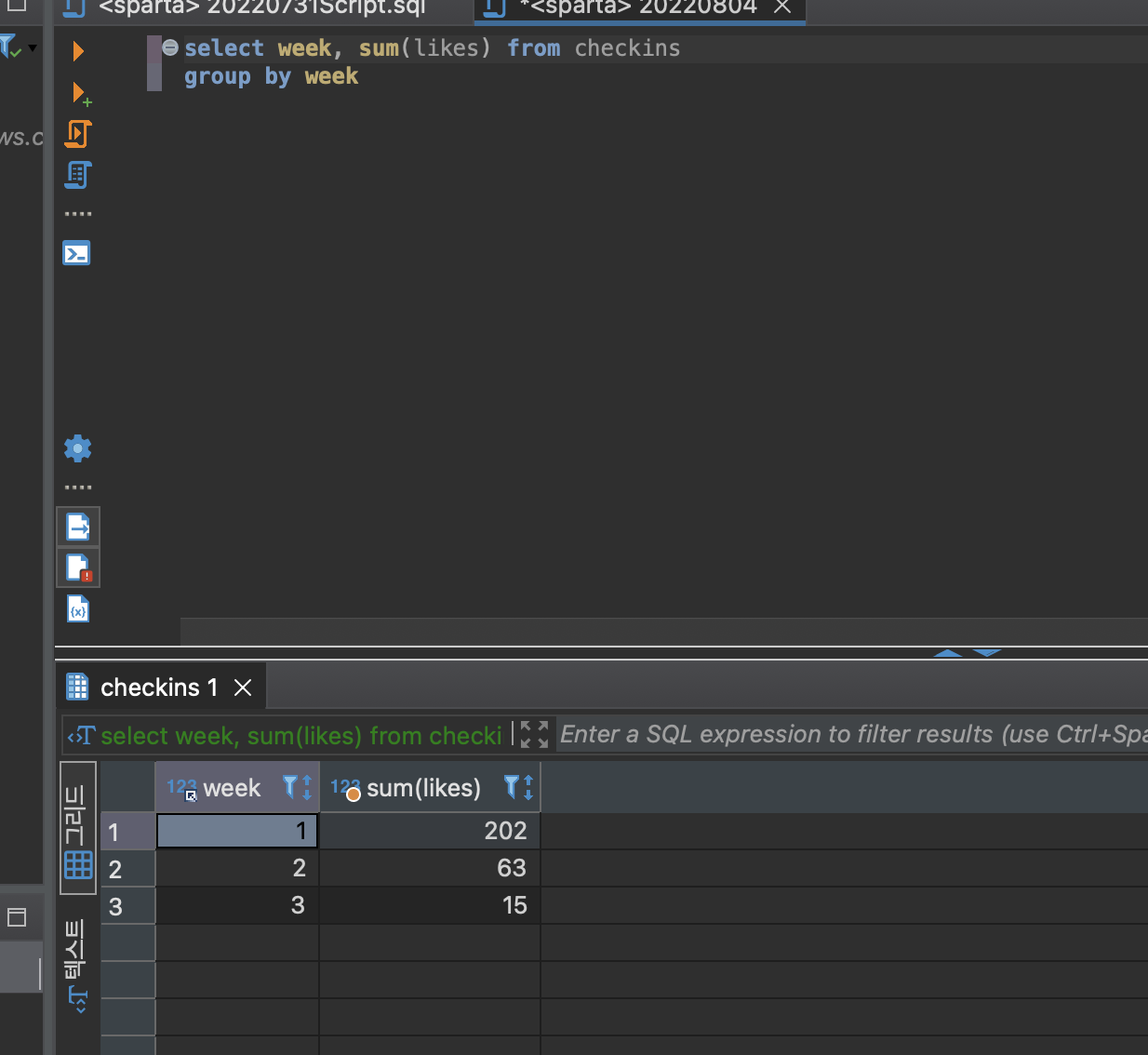
결과가 동일한지 where 문으로 검증을 해보면 되는데,
맞겠거니…
202개가 맞는지 한번 봐야 하나..
Where 구문을 써서 1주에 몇 개의 다짐이 있는지 봤더니 96개였다.
likes의 합계가 202가 나온 건.. 다 더해봐야 하나…
아… 나 수학을 못하지.
이건 엑셀에 넣고 다 더해보면 202 가 나오지 않을까 ㅋㅋㅋㅋㅋ
암튼, count, min, max, avg, round, sum의 명령어를 잘 알고 있으면 된다.
2. order by
order by 즉, 정렬에 대해서 배운다.
users 테이블에 뭐가 있는지 확인을 한 뒤
이름과 숫자를 세야 한다고 치면
select name, count (*) from users
group by name
하면 이름과 숫자가 쭉 뜨는데,
이것을 오름차순과 내림차순으로 정렬을 해주고 싶다면 order by를 쓴다.
기본은 오름차순이다.
select name, count(*) from users
group by name
order by count (*)
라고 써주면 된다
내림차순을 하고 싶다면, descending의 약자인 desc이다.
오름차순을 하고 싶다면ascending의약자인 asc인데 이건 기본형이니깐안 써도 된다.
나는 이때부터 오름차순과 내림차순의 딜레마에 빠지게 된다 ㅋㅋㅋ
내림차순은 큰 숫자부터 내려오는 거 오름차순은 작은 숫자부터 내려오는 건데,
내리고 올리고의 방향에 맞춰 머릿속으로 계속 내림차순 하고 있었다 ㅋㅋㅋㅋ
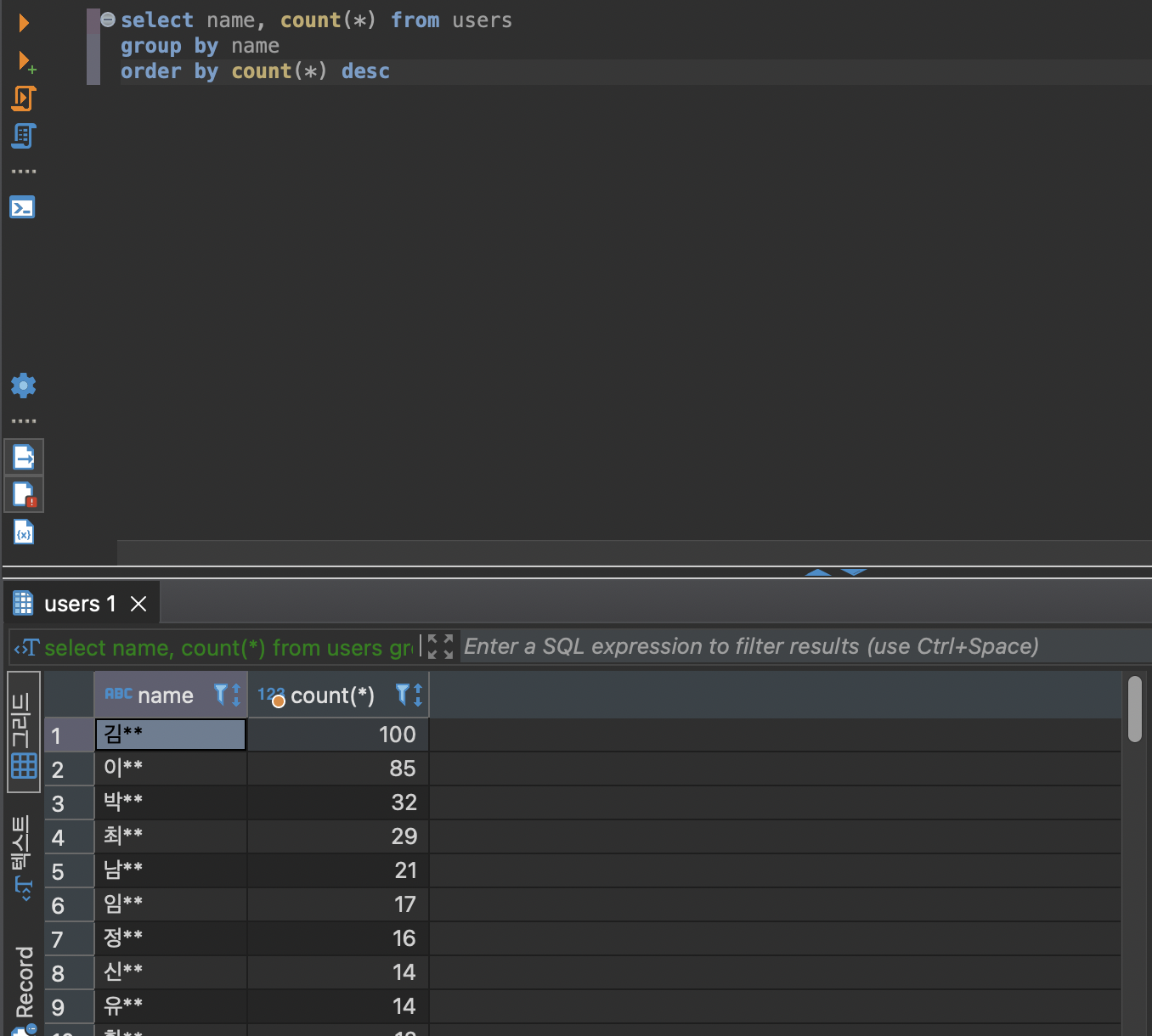
내림차순을 해주기 위해 desc를 써주었다.
이렇게 큰 숫자부터 쭉 작은 숫자들로 내려온다.
역시 한국은 김이박…
Order by는 항상 group by와 같이 쓰는 것인가?
아니다.
데이터에 따라 다르다.
checkins 데이터에서 가령 like의 개수 같은 경우,
따로 묶지 않고 그냥 유저별로 보는 것이 더 좋은 데이터라
그냥 order by를 쓰면 된다.
내림차순으로 보면
Order by 뒤에 바로 likes를 써서 본다. 내림차순이니까 desc를 써서.
그러면 like가 가장 많은 것부터 쭉 내려온다.
쿼리가 실행되는 순서를 생각해볼 때,
Group by로 묶으면
From -> group by -> select -> order by 순으로 실행된다.
한 개의 쿼리가 끝났을 때, 세미콜론을 쓰기도 한다. 여기서는 안 써도 되지만..
웹 개발할 때 워낙 잘 빼먹는 터라 이것도 습관을 들여두면 좋지 않을까 싶은데. 뭐.
여기서 말하는 한 개의 쿼리란
데이터 값을 뽑아내는 최종 덩어리들을 말한다.
Select name, count(*) from users
Group by name
Order by count (*);
이렇게 덩어리가 끝날 때 한 번만 쓰면 되나 보다.
기초에서는안 써도 된다.
3. Where과 group by, order by 같이 쓰기
만약에 결제수단별 유저의 숫자를 파악하고 싶다면?
Select * from orders
에서 자료를 한번 본다.
Payment method에서 카드결제인지 카카오페이인지 등등을 알 수 있는데 숫자를 세고 싶으니까
Group by로 묶어준다.
Select * from orders
Group by payment method
이렇게 쓴 후 여기서 * 위치에 payment method, count (*)를 써준다.
이때 payment method를 안 쓰면 어떻게 되느냐?
오류는 나지 않는다. 다만, 어떤 것의 결과값인지를 파악할 수 없게 된다.

어떤 그룹을 지정해 줬다면, 그 그룹을 선택해서 보여주는 것이 인지상정인 것이다.
그리고 만약에
전체 유저의 결제수단이 아니라
웹 개발 종합반만 따로 결제수단별 인원을 파악하고 싶다면
where을 같이 쓴다.
Where는 group by 보다 먼저 써준다. 실행 순서도 아마 먼저일 것이다.
where로 위치를 지정해주고 그룹으로 묶어서 select 해서 실행되는 것이다.
쓰는 순서는 앞서 말했듯,
Select * from orders를 먼저 실행해 데이터 확인을 해서 어디를 중심으로 잘라서 묶으면 될지 지정해준다.
where로 지정 필드명을 중심으로 해달라는 명령을 먼저 한다.
그리고 Group by 지정 필드명 해준 뒤에 select 뒤에 붙은 * 대신 지정 필드명, count(*)를 넣으면 되는 것이다.
만약에 count 부분을 1 3 22 107 순서로 등장시키고 싶다면, Order by를 써준다.
기본 오름차순 순서이므로 그냥 하단에 order by count(*)을 기입해주면 끝이다.
숫자로 된 데이터만 정렬을 할 수 있는 것은 아니다.
두둥.
이메일을 알파벳순으로 정렬할 수도 있다.
이메일을 도메인들끼리 묶어서 볼 수도 있다.
이메일을 order by 했더니 a부터 쭉 정렬되었다.
이름순으로 했을 때도 오름차순이 기준이라 ㄱ으로 시작하는 이름부터 쭉 정렬될 것이다.
데이터 값이 존재한다면, 언제부터 가입했는지도 파악이 가능하다.
그저 보고자 하는 데이터 파일에서 어떤 필드를 쭉 정렬해서 보고 싶은지를 order by를 써서
정리할 수 있는 것이다.
퀴즈 1. 앱 개발 종합반의 결제수단별 주문 건수 세어보기
where로 범위를 딱 지정해주는 게 좋다.
퀴즈 2 gmail을 사용하는 성씨별 회원수 세어보기
지난주에 썼던 where like를 쓰면 된다.
기억이 안 나서 찾아서 썼다. ㅠㅠ
Where email에서 like ‘% gmail.com’ 할 거라고 지정해주면 된다.
%만 기억에 남고 like의 위치 때문에 오류 ㅋㅋㅋㅋ
퀴즈 3 course_id 별 오늘의 다짐에 달린 평균 like의 개수?
정말 힘들었다.
답을 보고서 답이 나올 때까지 고치고 고친 쿼리.
체크인 데이터에서 코스 아이디별 좋아요 개수의 평균을 알고 싶으니
우선은 코스 아이디만 보고 싶어서
Select * from checkins
Group by course_id
하면 두 개가 나왔다.
좋아요의 평균만 보면 되기 때문에
Select에 course_id, avg(likes)를 넣어줬다.
그랬더니 됐다.
소수점 첫 번째 자리까지만 보고 싶을 때는 round를 써준다.

쿼리를 이용해 데이터를 뽑고 싶을 때,
Show tables 해서 데이터를 먼저 확인하고
Select * from 필드명 해서 확인을 해본다.
어떤 필드가 보고 싶은지 어떤 범주로 묶으면 될지 등등 생각해서 작성하면 되겠다.
4. 별칭 alias (알리아스)
지금은 짧지만 길어질 쿼리에 별칭을 붙여서 구분하는 것을 배워야 한다.
테이블에다가 별칭을 줄 수 있다. 테이블마다 필드명이 같을 때는 테이블마다 구분을 해야 한다.

어쩐지 컨트롤 엔터를 칠 때마다 from뒤에 뭔가가 따라붙더라니…
orders를 o라고 부르겠다는 의미라고 한다.
o. course_title 은 o 테이블 안에 있는 course_title이라고 구체적으로 지정이 가능한 것이다.
Group by 해서 count 숫자를 보는 것까진 좋은데 count(*)의 모양 자체가 별로라면
이를 별칭으로 지칭해서 바꿀 수도 있다.
바로 as 별칭을 붙이면 된다.
Select 필드명, count(*) as 별칭 from 데이터명
별칭을 cnt라고 했더니 cnt로 띄워준다.

끝으로 숙제가 있었다.
- 네이버 이메일을 사용하여 앱 개발 종합반을 신청한 주문의 결제수단별 주문건수 세어보기
Where와 and와 like를 잘 써야… ㅋㅋㅋ
그룹으로 묶고 카운트했는데 오류가 떠서 당황했다.
아니 틀릴 리가 없는데???
띄어쓰기가 잘못됐었나 보다..
휴.. 어쨌든.
오늘은 노트한 거 복붙 한 개발일지이다.
쿼리는 아직은 짧아서 수업내용도 간결하고 비교적 빨리 들을 수 있었지만
3주 차 때는 어떨지 모르겠다.
원하는 결괏값이 안 나올 때는 나도 모르게 "왜?"라고 물으며 컴퓨터와 대화를 시도했다.
왜긴 왜야.. 내가 틀린 것이지.. 흑흑 ㅠㅠ
웹 개발 수업이 좀 타이트하기 때문에 쿼리는 빨리빨리 해치워 버리겠다며.
'개발일지' 카테고리의 다른 글
| [내일배움단] SQL 데이터 분석 강의 3주차 (feat. 스파르타코딩클럽) (0) | 2022.08.10 |
|---|---|
| [강의 후기] 나는 개발자가 되고 싶은걸까? (0) | 2022.08.10 |
| [내일배움단] 웹개발 종합반 2주차 (feat. 스파르타코딩클럽) (0) | 2022.08.07 |
| [내일배움단] 웹개발 종합반 1주차 (feat. 스파르타코딩클럽) (0) | 2022.08.03 |
| [내일배움단] SQL 데이터분석 강의 1주차 (feat.스파르타코딩클럽) (0) | 2022.07.31 |




댓글